มาทำ Image Captioning ช่วยคนตาบอดกัน !!
เคยคิดไหมว่าคนพิการเขาใช้ชีวิตกันอย่างไร โดยเฉพาะคนที่พิการทางสายตา ซึ่งไม่สามารถมองเห็นได้เลย หรืออาจมองเห็นได้บ้างไม่มากนัก คนเหล่านี้ไม่สามารถมองเห็นสิ่งต่างๆ ที่เกิดขึ้นรอบตัวได้เหมือนพวกเรา และไม่สามารถรับรู้ถึงสีหน้าอารมณ์ของผู้ที่กำลังคุยด้วยได้ ดังนั้น Image Captioning อาจเป็นทางออกทางหนึ่งที่จะช่วยทำให้คนตาบอดสามารถรับรู้ถึงรูปร่าง ท่าทาง สีหน้า อิริยาบถต่างๆ ของสิ่งต่างๆ ที่เกิดขึ้นได้ !

แล้ว Image Captioning คืออะไร ?
Image Captioning คือ กระบวนการสร้างคำอธิบายให้กับรูปภาพ โดยใช้ Computer Vision และ Natural Language Processing (NLP) ในการสร้างโมเดลขึ้นมา
ตัวอย่างเช่น เรามีรูปผู้หญิงที่กำลังดื่มกาแฟแล้วยิ้ม เราก็ป้อนรูปนี้เข้าไปในโมเดล Image Captioning

แล้วตัวโมเดลก็จะ predict ว่าในรูปมีอะไร และกำลังทำอะไรอยู่ อย่างในตัวอย่างโมเดลก็ predict และเขียนเป็น caption ออกมาว่า “ผู้หญิงในชุดสีเทากำลังยิ้ม”

พูดง่ายๆ ก็คือ เป็นการแปลงจากรูปให้ออกมาเป็นข้อความนั่นเอง
Image Captioning ทำงานยังไง?
โดยหลักการของการทำ Image Captioning จะใช้เป็น Encoder-Decoder Model คือ ประกอบไปด้วยโมเดลย่อย 2 ส่วน
- Encoder จะทำหน้าที่แปลความหมายของรูปภาพให้อยู่ในรูปเวกเตอร์ทางคณิตศาสตร์ ซึ่งเป็น CNN (Convolution Neural Networks)
- Decoder จะทำหน้าที่ถอดความหมายที่ซ่อนอยู่ในเวกเตอร์ทางคณิตศาสตร์ ให้ออกมาในรูปคำบรรยาย (โปรเจคนี้เลือกให้คำบรรยายเป็นภาษาไทย) Decoder เป็น RNN (Recurrent Neural Networks) ซึ่งเลือกที่จะใช้แบบ GRU (Gated Recurrent Unit)

นอกจากนี้ยังมีการใช้ Attention-based model ซึ่งช่วยให้เราเห็นว่าส่วนใดของภาพที่โมเดล focus ขณะที่สร้างคำบรรยาย

เลือกใช้ Dataset สำหรับ train โมเดล
Dataset ประกอบด้วย 2 ส่วน คือ ส่วนที่เป็น images และ ส่วนที่เป็น captions โดย 1 image จะมี 5 captions
โปรเจคนี้ใช้ dataset จาก kaggle ซึ่งมีขนาดไม่ใหญ่จนเกินไป
สามารถ Download Dataset ได้ที่ https://www.kaggle.com/adityajn105/flickr8k

เนื่องจาก captions ใน Dataset นี้เป็นภาษาอังกฤษ จึงต้องทำการแปลเป็นภาษาไทยก่อน โดยใช้ Python Library pythainlp ในการแปล

ต่อมาเป็นการ Preprocess Data ซึ่งแบ่งได้เป็น 2 ส่วน คือส่วนของรูปภาพ และส่วนของคำบรรยาย
Preprocess Images
ในขั้นตอน Preprocess รูปภาพ เราจะใช้ InceptionV3 ซึ่งเป็น pretrained โมเดลการจดจำรูปภาพที่ใช้กันอย่างแพร่หลายบนชุดข้อมูล ImageNet มาแยกแยะรูปภาพ extract features และเก็บเป็นเวกเตอร์ใน Dictionary
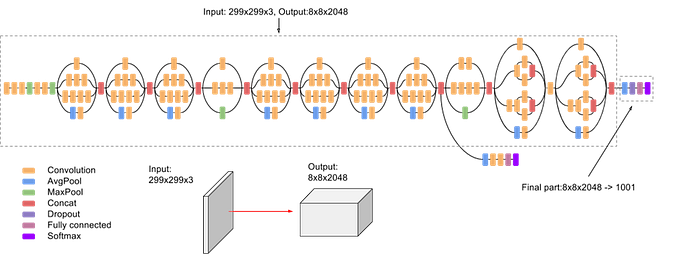
Preprocess Captions
ในการ Preprocess แคปชั่น อย่างแรกเลย เราต้องทำการ Clean data ก่อน เนื่องจากภาษาไทยนั้นไม่มีการใช้ comma ในการแบ่งประโยคหรือ list ตัวอย่างเหมือนในภาษาอังกฤษ ดังนั้นเราจึงต้องกำจัด comma จาก captions ของเราออกให้หมดก่อน จากนั้นก็นำ captions เหล่านั้นมาเก็บในรูปของ list เพื่อนำไป Tokenize ต่อ
โดย Tokenization นั้นก็คือ การนำข้อความยาวๆ มาแตกออกเป็น คำๆ เป็น Token ซึ่งถือว่าเป็นขั้นตอนที่สำคัญในการทำ Natural Language Processing (NLP) มากๆ เพราะสามารถนำไปสร้าง Bag of words (คลังคำศัพท์) ไว้ให้ตัวโมเดลเลือกใช้ตอนที่จะสร้าง caption ได้
เนื่องจากประโยคภาษาไทยจะเขียนติดกัน ไม่เหมือนกับภาษาอังกฤษ ดังนั้นในการ Tokenize ภาษาไทย จึงต้องใช้ tokenizer สำหรับภาษาไทย ซึ่งในที่นี่เราใช้ของ pythainlp โดยเลือกใช้ engine ชื่อ “newmm”
ตัวอย่างเช่น “ฉันกินข้าว” tokenize ออกมาจะได้เป็น “ฉัน” , “กิน”, “ข้าว”
หลังจากนั้น เราก็รวมศัพท์ทั้งหมดที่ได้จากการ tokenize มาสร้าง Bags of words (คลังคำศัพท์) โดยแต่ละคำก็จะมี ID สำหรับแทนคำๆนั้น

เราก็นำ ID ของคำแต่ละคำมาใช้แทนคำใน caption ของเรา เพราะ Input ที่ Feed ให้โมเดลต้องเป็นตัวเลขเท่านั้น ไม่สามารถเป็นตัวอักษรได้ แล้วเก็บในรูปของ list
เช่น จากตัวอย่าง “ฉันกินข้าว” สมมติเราได้คลังคำศัพท์เป็น
{“ฉัน” : 5, “ข้าว” : 8, “กิน” : 14}
พอนำ ID มาแทนคำในประโยค “ฉันกินข้าว” จะได้ [5, 14, 8] เราก็ทำแบบนี้ให้กับ captions เราทั้งหมด แต่เพราะแต่ละประโยคมีความยาวคำไม่เท่ากัน แต่เวลานำเข้า โมเดลต้อง fit ให้มันเท่ากัน เราจึงต้องทำการ Padding โดยการหาจำนวน Max Length และ เติม pad 0 ด้วยวิธี pad_sequences ด้านหลังประโยคที่มีคำน้อยกว่า Max Length ให้เต็ม
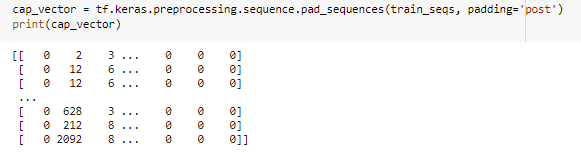
Split the Data into Training and Testing
เราต้องแบ่ง Data จำนวนนึงเป็นส่วนที่ให้โมเดล Train กับอีกส่วนนึงที่เอาไว้ Test เพื่อที่จะได้รู้ความแม่นยำของโมเดล โดยเราจะแบ่งจำนวน Train: Test เป็น 80:20
Model and Training
สำหรับโมเดลที่เราใช้ อย่างที่กล่าวไปจะใช้อยู่ 3 ส่วน คือ Encoder, Decoder และ Attention
ในส่วนของ Encoder ซึ่งใช้ CNN เนื่องจากเราได้มีการ Extract Features ของรูปภาพไปแล้วจากขั้นตอน Preprocess Images เราจึงเหลือแค่ Pass Features เหล่านั้นไปที่ Fully Connected Layer ได้เลย
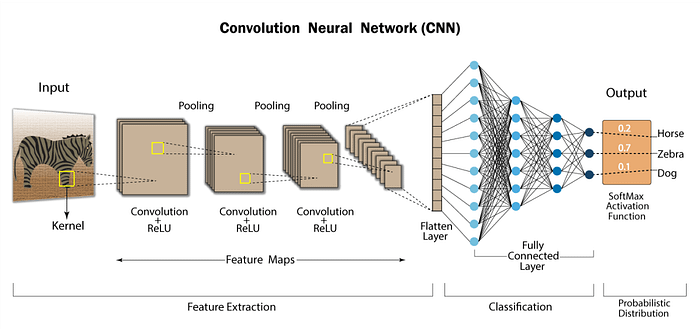
ส่วนของ Decoder ซึ่งเป้าหมายคือ Predict Token ตัวต่อไป จะรับ Encoder Output และใช้ RNN track สิ่งที่มันสร้างขึ้นมา และนำ Output เหล่านั้นไปสร้าง Context Vector หลังจากนั้นก็นำ RNN Output และ Contex Vector รวมกันโดยใช้สมการด้านล่าง ก็จะได้ Attention Vector ออกมา ซึ่งเอาไว้ใช้ Predict Tokens ตัวต่อไป

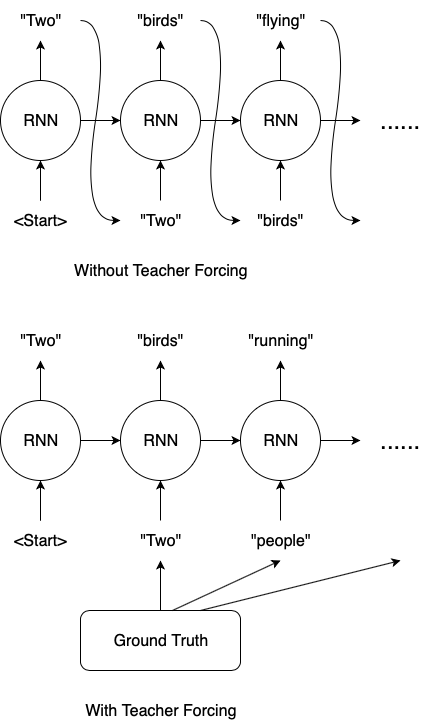
ค่า Prediction ก็จะถูกนำมาคำนวณค่า Loss ซึ่งในการเทรนปกติ จะนำ Output อย่างเดียวมา Feed เป็น Input สำหรับคำต่อไป ซึ่งถ้าโมเดลยังไม่ค่อยแม่น ก็อาจจะ Predict ผิดต่อเป็นทอดๆได้ ดังนั้นเราจึงใช้ Teacher Forcing ซึ่งเป็นการเทรนที่ Feed Output ทั้งที่แบบถูกต้อง กับ ของโมเดล (Prediction) ไปด้วย ทำให้โมเดลเรียนรู้ได้เร็วขึ้น สุดท้ายคือหาค่า Gradients เพื่อนำไปประยุกต์ใช้กับ Optimizer และ Backpropagation
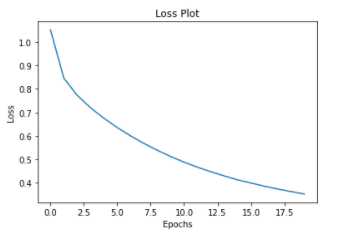
และนี่ก็คือ Loss Plot หลังจากที่ Train เสร็จนั่นเอง
Captioning
ในการที่จะสร้าง Caption เราควรจะรู้ด้วยว่าคำแต่ละคำที่โมเดลสร้าง มัน Focus ตรงไหนของรูปภาพ ซึ่งนั่นคือการใช้ Attention เราจึงสร้าง Function ให้โมเดล Plot Attention ออกมาด้วย แต่ทว่าปกติ Matplotlib ที่เราจะใช้ Plot นั้นไม่รองรับภาษาไทย เราจึงต้องเพิ่ม Font ภาษาไทยเข้าไปก่อน โดยดูวิธีการเพิ่มได้จาก https://colab.research.google.com/drive/1sTdTZx_Cm51mc8OL_QHtehWyO4725sGl
Result!
และแล้วเราก็ได้ Caption ที่สร้างโดยใช้โมเดล Image Captioning โดยรูปด้านล่างคือ Testing Data ที่เราแบ่งไว้ก่อน Training จะเห็นว่า Prediction อาจจะมีผิดบ้างเทียบกับ Real Caption เนื่องจาก Dataset ที่เราใช้ขนาดไม่ใหญ่มาก ซึ่งเราสามารถแก้โมเดลของเรา หรือใช้ Dataset ที่มีขนาดใหญ่กว่านี้ได้


เราสามารถหาภาพจาก Internet ให้โมเดลลอง Predict ดูก็ได้


Metrics
สุดท้าย เราก็ต้องมีการวัดความถูกต้องของโมเดลเรา โดยเราจะใช้ BLEU Algorithm (Bilingual evaluation understudy) ซึ่งสามารถวัดความถูกต้องของ Predicted Caption ของเรา เทียบกับ Real Caption ได้ โดยเราจะใช้ BLEU score ของ NLTK ในการคำนวณ


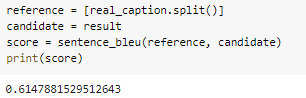
และนี่ก็คือ score ของการ Predict รูปนี้ ซึ่งมีความถูกต้องที่ 0.614


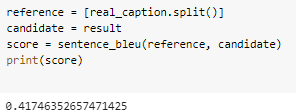
ส่วนรูปนี้ความถูกต้องอยู่ที่ 0.417 ซึ่งก็อย่างที่กล่าวไปว่าเราสามารถเพิ่มความถูกต้องได้ด้วยการเลือก Dataset ที่ใหญ่กว่านี้นั่นเอง
สรุป
สรุป Image Captioning คือการที่นำรูปภาพไปให้โมเดลสร้าง Caption หรือ คำบรรยาย โดยหลักการก็แค่นำส่วนของรูปภาพ (Computer Vision) และส่วนของคำพูด (Natural Language Processing) มารวมกัน ซึ่ง Image Captioning นั้นเป็น Task ที่สำคัญมากๆ ใน Field ของ Deep Learning เราสามารถนำไปประยุกต์ใช้ประโยชน์ได้กับหลายอย่างๆ โดยเฉพาะการช่วยคนตาบอดหรือคนที่มีปัญหาด้านสายตา ซึ่งเราสามารถให้โมเดลบรรยายภาพผ่านทางเสียงให้กับพวกเขาได้
สิ่งที่ได้เรียนรู้
สิ่งที่ได้เรียนรู้จากโปรเจคนี้คือ ความเข้าใจในเรื่องของ Computer Vision และ Natural Language Processing ตั้งแต่การ Preprocess Data ทั้งแบบ Images และ Captions, การใช้ Network ทั้งแบบ CNN และ RNN, การใช้ Attention และการ Debug Error ต่างๆ
Future Work
สำหรับงานในอนาคต จะนำโมเดลไปปรับให้มีความถูกต้องมากขึ้น และนำไป Deploy เป็น Web App หรือ Application ที่สามารถให้คนตาบอดใช้ได้จริง
